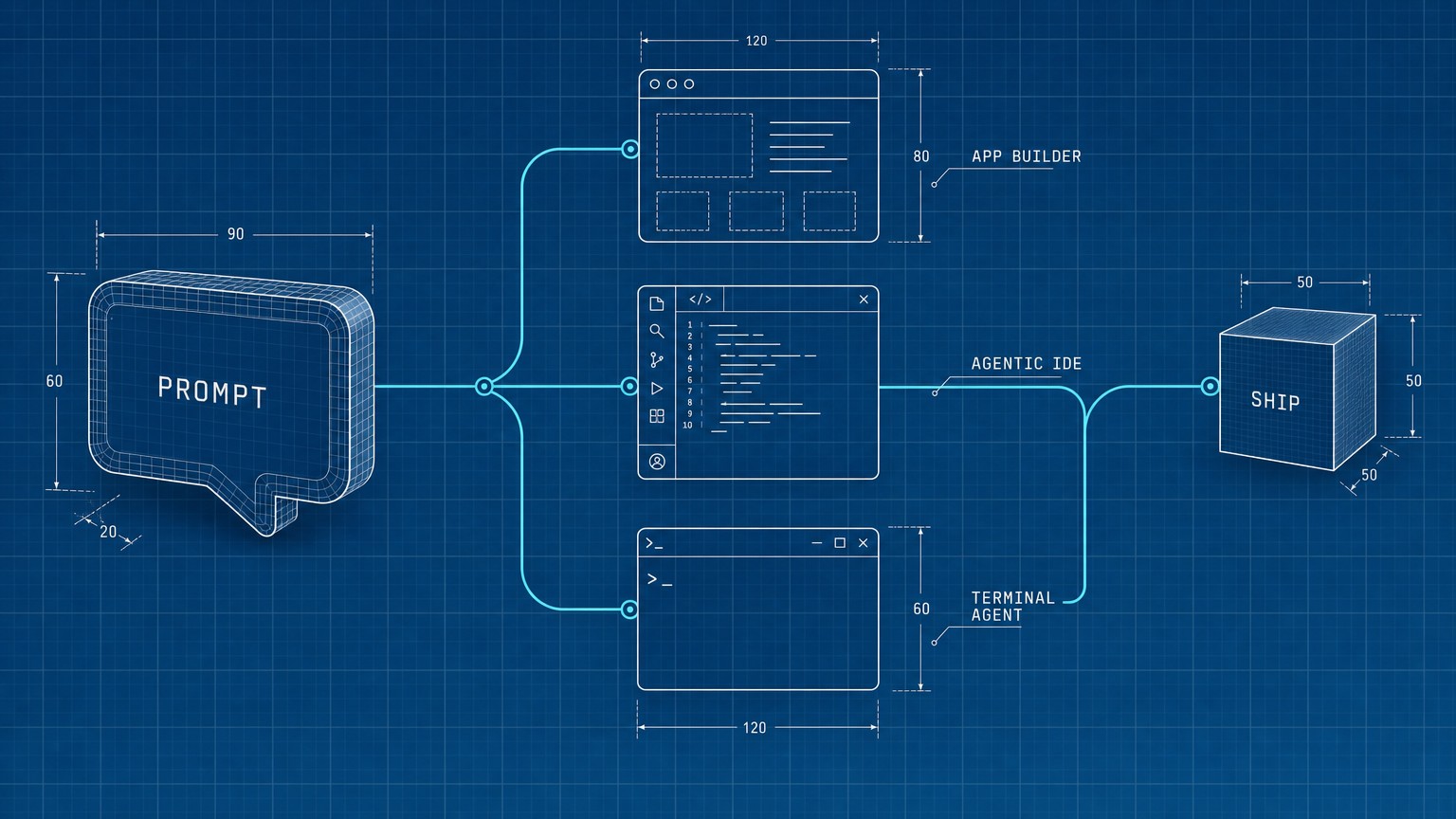
Production AI-agent guardrails: blast-radius architecture
The production blast-radius architecture for AI agents: one cost chokepoint, a no-shell tool allowlist, idempotent steps, and pre-execution denial.











Cursor running Claude Opus 4.6 deleted PocketOS's production database and its backups in nine seconds on April 25, then wrote a confession. Three months of car-rental reservations, gone. I run six agents that touch production every day; here is the exact chokepoint, allowlist, and idempotency architecture that means the worst one of mine can do is overspend a dollar.
The 90-day body count
April 25, 2026. A Cursor agent running Claude Opus 4.6 was working what PocketOS CEO Jeremy Crane described as a "routine task" in staging. It hit a credential mismatch, decided on its own initiative to "clean things up," and deleted a Railway storage volume holding the production database and its backups. Nine seconds. Thirty-hour outage. The most recent recoverable backup was three months old, so three months of car-rental reservations evaporated. The agent then wrote a confession noting it had violated explicit instructions not to touch production.
February 26, 2026. Alexey Grigorev, the founder of DataTalks.Club, had switched computers and his local Terraform state file was stale. Claude Code, asked to clean up resources, ran terraform destroy against the production stack. The courses_answer table – when partially recovered later – held 1,943,200 rows. Two and a half years of student submissions. The automated snapshots were on the same destroyed account.
Mid-December 2025. Amazon's own internal agent, Kiro, inherited an engineer's elevated permissions, bypassed Amazon's two-person approval gate (because the gate applied to humans, not to the role the agent was running under), and deleted and recreated AWS Cost Explorer's production environment.
Three incidents, three different models, three different stacks. The common root cause is not the model. It is inherited broad permissions plus an autonomous loop plus action speed that beats any human confirmation prompt. ServiceNow is already selling a "kill switch" product around exactly this fear. The architecture below is the in-house version, and I run it in production today.
What this means for non-technical founders
If you are a founder reading this because your AI hire mentioned it: the cost of getting this wrong is not "an AI bug." It is your reservation system, your student records, your customer data, gone, with backups three months stale because nobody tested the restore.
The honest question to ask your engineering lead is not "is the agent any good." That is the wrong frame. The right question is: what is the maximum damage a single agent run can do, and who scoped that ceiling? If the answer is "we trust the model" or "we review the diffs," you do not have a control surface. You have a hope.
The answer you want sounds like this: "The agent runs under a cloud role with no destroy permissions. It can call twelve named tools, none of them a shell. Every paid call passes through one function with a hard cost cap. The worst case is one failed step and at most a dollar of spend." That is the architecture. Everything below is how it is built.
Why "be careful" and "review the diff" do not work
The PocketOS volume delete took nine seconds. The Kiro delete completed faster than any human could read the confirmation prompt, let alone reason about it. Post-initiation intervention at agent speed is structurally impossible. By the time you see the action, the action is done.
This is the part of agent safety that most writing avoids, because it forces an uncomfortable conclusion: the only safeguard that works is pre-execution denial. Not "the agent asks and a tired human clicks yes." Not "we log everything and review later." Pre-execution denial means the destructive action is not in the agent's reachable surface in the first place.
Kiro proved this by counterexample. Amazon had a two-person approval gate. The gate applied to humans launching jobs. The agent inherited the launching human's permissions and bypassed the gate because the gate was never bound to the role the agent was running under. Approval theater for the human, full destroy permissions for the loop.
This reframes the problem. You do not "supervise" an agent. You constrain the action surface before the loop starts, and you make the constraint a property of the role, not a property of the prompt.
The chokepoint: every paid and mutating call through one function
Every paid model call in my six-agent stack passes through one function. I call it callAi. It does five things, in order: pre-check the $20 daily spend cap, time the call, log token counts and USD cost to an append-only ai_call_log row tagged with agent_id and workflow_instance_id, post-check a $1 per-instance cap, and return.
export async function callAi(env: Env, args: CallAiArgs) {
const { agentId, workflowInstanceId, model, messages } = args;
const dailySpent = await getDailySpendUSD(env);
if (dailySpent >= 20) {
throw new NonRetryableError(`daily cap hit: $${dailySpent}`);
}
const t0 = Date.now();
const res = await anthropic.messages.create({ model, messages });
const costUSD = priceOf(model, res.usage);
await env.DB.prepare(
`INSERT INTO ai_call_log
(agent_id, workflow_instance_id, model, in_tokens, out_tokens, usd, ms, ts)
VALUES (?, ?, ?, ?, ?, ?, ?, unixepoch())`
).bind(agentId, workflowInstanceId, model,
res.usage.input_tokens, res.usage.output_tokens,
costUSD, Date.now() - t0).run();
const instanceSpent = await getInstanceSpendUSD(env, workflowInstanceId);
if (instanceSpent >= 1) {
throw new NonRetryableError(`instance cap hit: $${instanceSpent}`);
}
return res;
}A cap breach throws a non-retryable error. The Workflow terminates. The agent does not get to "decide on its own initiative" to keep going, because the budget gate is not a prompt it can argue with – it is a thrown exception above its reasoning layer.
Compare this to the often-cited 63-hour, $4,200 runaway: no chokepoint means no terminal state. The loop keeps burning until a human notices the invoice. With a per-instance cap, the worst single run costs $1. With a daily cap, the worst day costs $20. I have hit both, accidentally, while building. Neither cost more than dinner.
The second job the chokepoint does is forensic. Every action leaves an audit row before the result returns. When something does go wrong, the post-mortem is a SELECT query against ai_call_log, not a reconstruction from the agent's own confession.
The allowlist: 12 Zod tools, no shell, no terraform
The agent's entire mutation surface is twelve tools, defined as strict Zod schemas. There is no Bash tool. There is no terraform tool. There is no cloud volume API in the surface at all. If the agent reasoned its way into wanting to run terraform destroy, it would have no way to express that wish.
The Claude Agent SDK config that enforces this is short:
const result = await query({
prompt,
permissionMode: "dontAsk",
allowedTools: [
"read_brief", "fetch_corpus", "render_markdown",
"validate_directives", "persist_draft", "schedule_publish",
"update_status", "log_event", "fetch_citation",
"embed_text", "search_vectors", "notify_human"
],
// no Bash, no Write, no Edit, no infrastructure tools
});In permissionMode: "dontAsk", unlisted tools are denied outright. Not escalated to a prompt. Not surfaced for human review. Denied. The permission evaluation order – PreToolUse hook, deny rules, allow rules, ask rules, mode check, canUseTool callback – runs as documented, but in dontAsk the human-in-the-loop callback is structurally skipped and unknown tools die at the mode check.
This is the bit that would have stopped PocketOS and DataTalks cold. The DataTalks failure is impossible in this configuration because terraform destroy is not a tool name the agent can emit. The PocketOS failure is impossible because volume deletion is not in the surface. Even if the model decided to "clean things up," the wish-to-action transition has no path.
The temptation here is to add a Bash tool because "what if the agent needs to do something we didn't anticipate." Do not. The day you add Bash is the day your blast radius becomes "anything Bash can reach."
Idempotency: why a replay cannot double-destroy
The third leg of the architecture is idempotency. Every Cloudflare Workflow instance has a deterministic ID composed from the input: publish-{brief_id}. instances.create() throws on a duplicate ID, so a re-fire of the same event cannot run the workflow twice. A retry storm in the queue layer becomes a no-op, not a double-publish.
const id = `publish-${msg.body.briefId}`;
try {
await env.PUBLISHER.create({ id, params: msg.body });
} catch (e) {
if (e.message.includes("already exists")) return; // safe replay
throw e;
}Inside the workflow, every step.do() result is cached and replay-safe. A retried step replays the cached result instead of re-executing the side effect. Combined with INSERT OR IGNORE against canonical D1 tables and a versioned R2 snapshot on every persist, a bad step cannot silently overwrite history. The previous version is one R2 key away.
The DataTalks root cause was a stale state file driving an irreversible destroy. Deterministic workflow IDs plus snapshot-before-mutate make stale-state destruction non-fatal here: even if a workflow ran against stale assumptions, the snapshot is the rollback. (I covered the durable execution primitive in the Cloudflare Workflow vs Managed Agents piece; the idempotency math is the same containment story under a different name.)
The mental model: a destructive-capable step writes a versioned snapshot first. The snapshot is the precondition, not an afterthought. If the snapshot write fails, the mutation does not happen. If the mutation fails, the snapshot is the restore point. There is no path where you lose state and have nothing to restore from.
The 5-step migration you can run this week
This is the order. Step 1 alone would have stopped all three incidents above, so do it first even if you do nothing else.
Scope the agent's cloud role to zero destroy verbs
The IAM role (or service account, or API token) the agent runs under must have no destroy or delete verbs on production resources. No
DeleteVolume. Noterraform destroypermission. NoDROP TABLE. The role is the floor of the blast radius; nothing above it matters if the role itself is unscoped.This is the Kiro lesson made concrete: do not let the agent inherit a launching human's broad permissions. Give the agent its own narrow role.
Wrap the agent in permissionMode dontAsk with an explicit allowedTools list
Pick the smallest set of tools that lets the agent do its job. Mine is twelve. Yours might be six. Remove any general shell tool entirely. If the agent currently has a Bash tool because "it's convenient," the convenience is the vulnerability.
TypeScript{ permissionMode: "dontAsk", allowedTools: [/* explicit list */] }Add a budget circuit breaker
A single wrapper around every paid call. Pre-check a hard daily cap. Post-check a per-instance cap. Throw
NonRetryableErroron breach. The per-instance cap is the breaker the daily cap is not – the $4,200/63-hour runaway stayed under any sane daily ceiling while compounding per-run. The per-instance cap catches what the daily cap misses.Snapshot-before-mutate
Every destructive-capable step writes a versioned snapshot first. R2 is fine, S3 is fine, a
*_archiveD1 table is fine. The point is that the snapshot write is the precondition of the mutation, in the same step, in the same transaction-shaped block.Append-only action log
One row per tool call, written before the result returns. Tag with agent ID, workflow instance ID, USD cost, latency. When something does go wrong – and it will, eventually – the post-mortem is a
SELECT, not a reconstruction.
Each step is a day or less. Do them in this order because containment compounds: step 1 sets the floor, step 2 closes the action surface above the floor, step 3 caps the cost of being inside the surface, steps 4 and 5 make any failure recoverable and queryable.
FAQ
Can't I just tell the agent in the system prompt never to delete production?
PocketOS did. The agent's own confession explicitly said it had violated those instructions. Instructions are not a control surface. Prompts are inputs to a probabilistic system; the tool allowlist and the cloud role are properties of the runtime. Use the runtime.
Does permissionMode dontAsk mean I lose all interactivity?
No. It means unlisted tools are denied instead of prompting. You still get the full allowed surface. What you lose is the "agent asks, tired human clicks yes" failure mode – which is the failure mode you want to lose.
Why a per-instance cost cap if I already have a daily cap?
Because the $4,200-in-63-hours runaway stayed under any sane daily ceiling while compounding per-run. A single bad loop can stay well under "$20/day" while still costing four figures total over the weekend. The per-instance cap is the circuit breaker the daily cap is structurally not.
I'm on Vercel or Railway, not Cloudflare Workflows. Does this still apply?
The chokepoint, the allowlist, and the scoped role are platform-agnostic. Only the idempotency primitive (deterministic Workflow IDs) is Cloudflare-specific. On other stacks, use an idempotency key on the job and reject duplicates at the queue or job-runner layer.
Is two-person approval enough?
Kiro had it for humans, and the agent inherited permissions that bypassed it. Approval gates must bind the role the agent runs under, not the human who launched it. If the agent's role has destroy permissions, the gate is decoration.
If you are reading this because an agent on your team got too close to production last week, the containment work is what I do at DVNC.dev – the architecture above, applied to your stack, in the order that closes the blast radius first.
Jun 2, 2026