FLUX.2 for designers (2026): the variants, the cost, and where it breaks
A designer's read on FLUX.2: what the five variants do, which fits your work, real megapixel pricing, and the craft bar it still misses.

FLUX.2 is the AI image model you reach for when you need to control the output, not be surprised by it: hex-locked brand colors, the same character across ten frames, type that mostly survives, and weights you can run on your own GPU. It will not hand you a Midjourney mood. It hands you a workhorse.
The verdict: a controllable workhorse, not an aesthetic oracle
If your job is repeatable, on-brand production imagery, FLUX.2 is the strongest open-weight option shipping right now. Black Forest Labs, the Freiburg team behind Stable Diffusion, released the family on November 25, 2025, then added the small [klein] models on January 15, 2026. What makes it a design tool rather than a toy is the control surface: you can pin exact brand colors with hex codes, hold a character or product consistent across multiple generations by feeding up to ten reference images, and fine-tune the model on your own visual style with LoRA training. A LoRA is a small add-on file that teaches a base model one specific look without retraining the whole thing.
What it is not is an aesthetic oracle. Midjourney still produces a more finished, more "designed" frame out of the box, and Google's Nano Banana edits photos more cleanly. FLUX.2 trades that surprise-me magic for predictability, and for designers that is usually the better deal: a slightly plainer image you can reproduce exactly beats a gorgeous one you can never get back.
The fast call: run [klein] 4B if you want to generate commercially on your own hardware for free, [pro] for hosted production work, [flex] when the image is mostly type, and [max] only for hero shots where quality outranks cost.
What FLUX.2 actually is
FLUX.2's real upgrade is a brain transplant. Where most image models use a small, dumb text encoder to read your prompt, FLUX.2 reads it with Mistral Small 3.1, a 24-billion-parameter vision-language model, then feeds that understanding into a rectified flow transformer. (A flow transformer is the engine that turns noise into an image; the "rectified" part just means it takes a straighter, faster path to get there.) The whole [dev] model lands around 32 billion parameters, and it is a single checkpoint that both generates new images and edits existing ones, no separate tool needed.
The practical payoff of the bigger language brain: it actually understands a dense prompt. Ask for "a glass of water on a wooden table in afternoon light" and it gets the refraction, the warm directional shadow, and the wood grain right more often, because the Mistral model carries real world knowledge instead of guessing from statistics. It also accepts structured prompts as labeled fields (subject, environment, lighting, color palette, style), which is closer to a creative brief than a sentence.
Two numbers matter for production. Native output goes up to 4 megapixels, enough for web and most social without upscaling, and you can condition a generation on up to 10 reference images at once, which is the mechanism behind character and product consistency.
The five variants at a glance
This is the part the spec-dump pages get wrong: the five variants are not a quality ladder you climb, they are five different jobs. Prices are Black Forest Labs' official per-megapixel API rates; a megapixel (MP) is roughly a 1000x1000 image, so a standard 1MP generation costs about the listed price.
[klein] 4B is the one most designers should start with. It is the only variant under an Apache 2.0 license, which means you can run it on your own machine and sell the output with no strings. It distills the big 32B model down to 4 billion parameters, runs on a consumer card with about 8GB of VRAM (an RTX 3090 or 4070), and renders in under half a second. Hosted on the BFL API it starts at $0.014/MP; on fal you can also rent an undistilled "Base" version at $0.009/MP that trades speed for the ability to tune quality and train LoRAs.
[pro] is the production default. At $0.03/MP for generation it sits at the top of the LM Arena image leaderboard, around a 1265 ELO on the v1.1 update, level with GPT Image. It supports up to 8 reference images on the API and renders in four to eight seconds. If you are generating ad variants or product shots through a hosted pipeline, this is the line item.
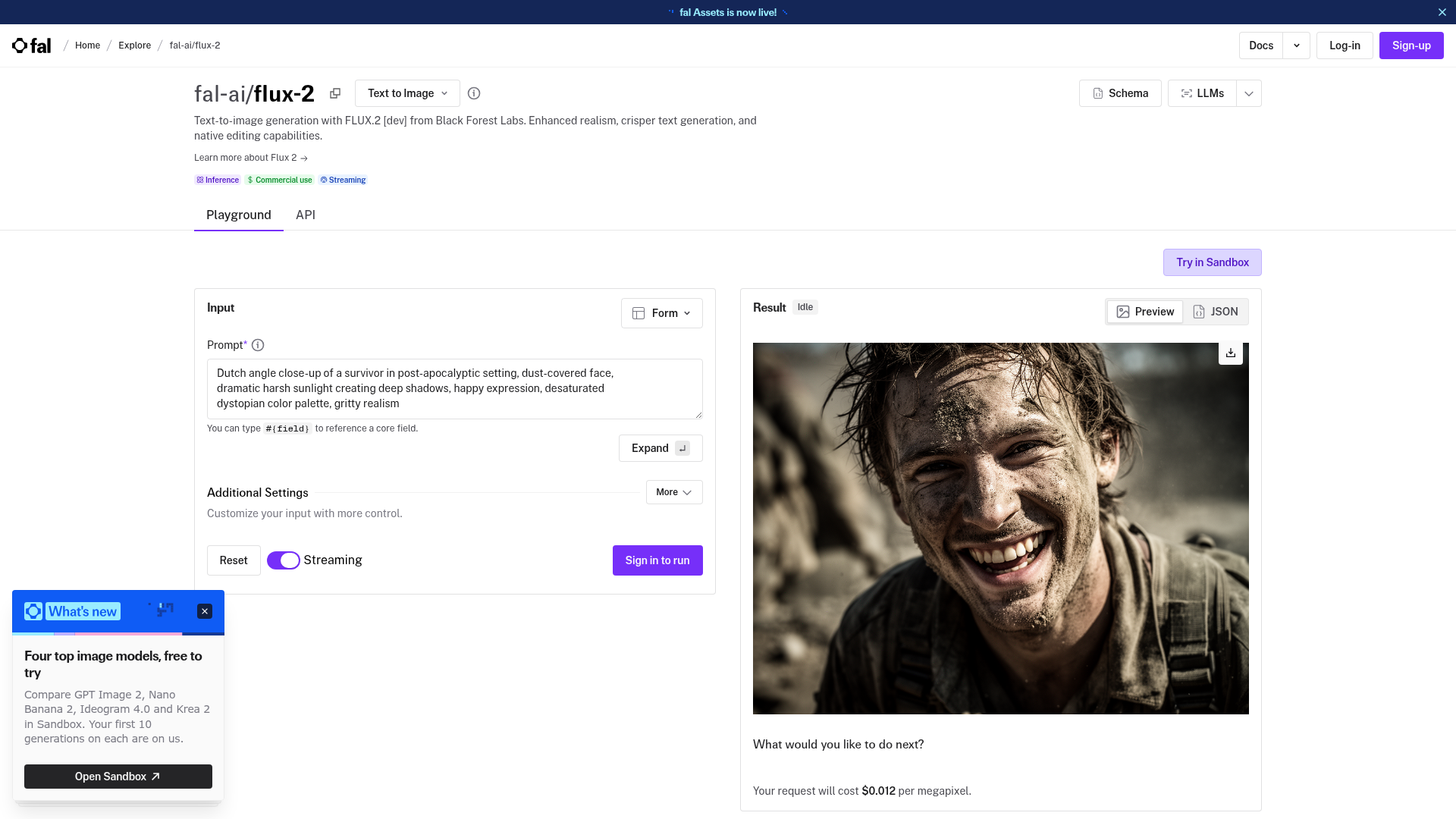
[flex] exists for type. Most image models still mangle text, and [flex] is Black Forest Labs' answer: it exposes the sampling steps and guidance scale so you can push the model harder on legibility, and it is tuned for multi-level typography, infographics with real numbers, UI mockups, and dense lettering. At $0.05/MP it is the one to reach for when the image is a poster, a chart, or a screen, not a scene. It also accepts LoRA weights, so a brand can bake in its own type system.
[max] is the print-and-hero variant. Same 32B architecture run at full quality with no shortcuts, from $0.07/MP, with one trick the others lack: real-time web grounding. It can search the web mid-generation to get a just-launched product's packaging or a current event right, instead of inventing it from frozen training data. Use it sparingly, for the one frame that goes large.
[dev] is the open lab. The 32-billion-parameter weights are free to download from Hugging Face under a non-commercial license, the most capable open-weight image model by parameter count at release. There is no hosted BFL endpoint; you run it yourself. Full precision wants 80GB of GPU memory, but a 4-bit quantized version fits in about 20GB on an RTX 4090. Quantization shrinks the model by storing its numbers at lower precision, trading a little quality for a much smaller footprint. This is the variant for fine-tuners and researchers, not for someone who just wants an image.
Where it breaks on a real brief
The honest cons, because every variant has them. Aesthetically it is competent, not magnetic. Run the same brief through Midjourney and FLUX.2, and Midjourney's frame usually looks more art-directed: better light, a stronger mood, a sense that someone composed it. FLUX.2 gives you something correct and controllable that often needs a second pass to feel intentional. For divergent mood-board exploration, that is a real gap.
Text still slips outside [flex]. The base variants render short, clean type reasonably well, but ask any of them for a paragraph, a logo lockup, or perspective lettering and you will get plausible-looking gibberish. [flex] narrows this but does not close it. Treat generated type as a placeholder you will rebuild in Figma or Illustrator, not as final art.
It rewards prompt density and punishes laziness. The Mistral brain is built for detailed, structured prompts. A three-word prompt gets you a generic result; the model genuinely improves when you specify subject, lighting, palette, and composition as separate fields. That is more work than typing a vibe into Midjourney.
[dev] is a hardware commitment. "Open weights" sounds free until you price the GPU. On a 4090 at 4-bit you are looking at roughly 15 seconds a megapixel; push it onto an 8GB card with offloading and a single image can take a minute or more. For most teams the hosted klein or pro endpoints are cheaper than the electricity and the wait.
- Hex color and multi-reference control most rivals do not expose
- klein 4B is genuinely free to ship commercially
- One model for both generation and editing
- LoRA fine-tuning for a locked brand style
- Top-tier prompt adherence from the Mistral language brain
- Less art-directed than Midjourney out of the box
- Text rendering still unreliable outside [flex]
- Needs dense, structured prompts to shine
- [dev] demands serious GPU hardware
- Five variants and three licenses is a confusing lineup
Which variant for your work
The right pick depends less on budget than on where the work lives and who has to own it.
The decision rule: if the output must be sold and generated on your own infrastructure, start at [klein] 4B for the Apache 2.0 license and only move up the variants when a specific job (typography, hero quality, web-current accuracy) forces it. Do not default to [max] because it is the best; you are paying five times klein's rate for quality most production work does not need.
For a sense of where FLUX.2 sits against the closed options, the comparison that matters most is Google's editor: see Nano Banana, explained for where a photo-native model beats it on clean edits.
Is FLUX.2 free?
Partly. The [dev] and [klein] models ship as open weights you can download and run for free, and [klein] 4B's Apache 2.0 license even lets you sell what you generate. The hosted variants ([pro], [flex], [max]) are paid per megapixel through the Black Forest Labs API, from $0.03 to $0.07/MP.
Is FLUX.2 open-source?
The weights for [dev] and [klein] are open; the code and the [pro]/[max] weights are not. Only [klein] 4B is under a true permissive license (Apache 2.0). [dev] and [klein] 9B use a non-commercial license that restricts the weights but lets you use the output commercially.
How much does FLUX.2 cost?
On the BFL API, from $0.014/MP for [klein] up to $0.07/MP for [max], with [pro] at $0.03/MP as the production sweet spot. If you run [dev] or [klein] on your own GPU, generation is free aside from hardware and power.
What is FLUX.2 good for?
Controllable, brand-consistent production imagery: ad variants, product photography, UI mockups, and anything needing locked colors or a repeated character or product across many frames. It is weaker for moody, art-directed exploration, where Midjourney leads.
Want the next model teardown the week it ships, with the real prices and the craft bar, not the hype? Subscribe to the newsletter and get each one in your inbox.
Jun 22, 2026






