Gemini Omni Flash Makes AI Video Feel More Like Editing
Gemini Omni Flash turns AI video into a prompt-and-edit workflow for clips, product videos, ads and social variants.

You can now treat AI video less like a slot machine and more like an editing session: make a clip, give it a reference image, ask for one change, then keep the parts that worked.
That is the real point of Gemini Omni Flash, Google's preview video model for the Gemini API. It does text-to-video, image-to-video, reference-based generation and follow-up edits through the Interactions API. The market already wants this badly: DFS shows 246,000 monthly Google searches for ai video generator, 40,500 for image to video ai and 27,100 for ai video editor.
What Gemini Omni Flash actually is
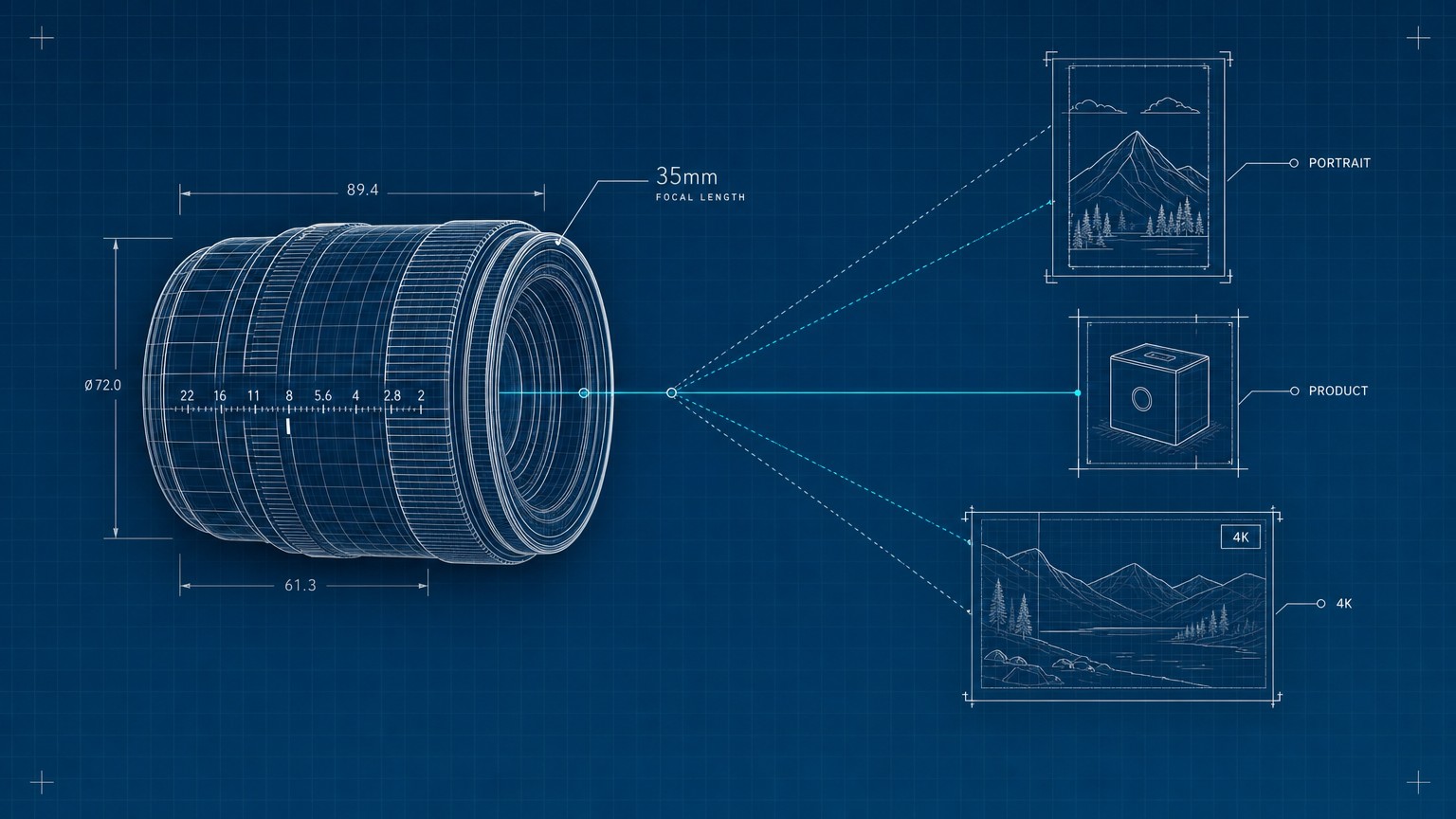
Gemini Omni Flash is Google's preview model for fast video generation and conversational editing. The model ID is gemini-omni-flash-preview, and Google positions it around three ideas: native multimodality, edit-by-conversation and world knowledge.
The easiest way to understand it is a film set with memory. A normal video generator is like hiring a crew, giving them a brief and hoping the first take works. Gemini Omni Flash is closer to keeping the crew in the room: you can say "make the lighting more dramatic" or "make the phone invisible" and ask for a new take without re-explaining the whole scene.
That memory comes from the Interactions API. An Interaction is one complete turn in a task. When you pass a previous_interaction_id, the server can retrieve the prior conversation history, including the generated video state, so the next request can build on it. In Omni's video workflow, each follow-up edit produces a new video.

The model accepts text prompts, reference images and uploaded video workflows. Google also describes the model as natively multimodal across text, image, audio and video, but the preview has a hard practical boundary: uploaded audio references are not supported in the current API version, and voice editing is not supported.
For output shape, aspect_ratio supports 16:9 and 9:16, with landscape as the default. For intent, generation_config.video_config.task can be text_to_video, image_to_video, reference_to_video or edit. If you leave the task unset, the model tries to infer what you meant from the prompt.
The price is not hobby-tier pricing. Gemini Omni Flash Preview is paid-tier only in the Gemini API. Google lists input at $1.50 per 1M tokens for text, image, video and audio. Output is $9.00 per 1M tokens for text and $17.50 per 1M tokens for video. Google says 720p video is billed at 5,792 output tokens per second, about $0.10 per second under Standard pricing.
How it works in plain language
The workflow is simple: describe the scene, optionally attach visual material, choose the video shape and keep edits narrow.
For a fresh video, you send a text prompt. Google recommends including the scene, camera movement, lighting and mood. If you want one continuous scene, say that directly: "single unbroken shot", "single continuous shot" and "no scene cuts" are the kind of instructions Google recommends.
For image-to-video, you attach an image and describe motion. A product photo might become a slow rotating hero clip. A sketch might become realistic footage. Google specifically warns against vague prompts like "make it move"; the stronger prompt describes subject motion, camera movement and environmental effects.
For reference-based work, you can pass multiple images. Google's example uses two image inputs, a cat and yarn, then asks for a clip of the cat playing with the yarn. The prompt guide also supports role tags: <FIRST_FRAME> can mark a starting frame, and <IMAGE_REF_N> can mark a reference image. Image references start at 0.
For edits, the best prompt is usually short. "Change the lighting to be more dramatic. Keep everything else the same." That final sentence matters because video models can otherwise treat your edit as permission to recompose too much of the clip.
For larger output files, Google recommends response_format.delivery="uri" for generated videos above 4 MB. That returns a Google-hosted URI, then your app polls until the file is ACTIVE before downloading it. For uploaded media, the Files API supports up to 20 GB per project, 2 GB per file and stores files for 48 hours. Google says to use the Files API when the total request is larger than 100 MB.
The use cases, ranked by who benefits first
1. Paid social teams making video variants
A performance marketer can start with a winning product shot, a short brief and a platform target like 9:16. Gemini Omni Flash can generate a video with sound, then the marketer can ask for small changes: tighter framing, different lighting, no dialogue, faster opening motion, one word appearing at a time.
The payoff is iteration speed. The expensive part of paid social is not one polished clip. It is the dozens of near-misses needed to find the version that earns its spend. Conversational edits fit that loop because the team can preserve the base scene while changing one variable at a time.
2. Ecommerce teams turning product images into motion
A Shopify store with hundreds of SKUs usually has still photos, not a production pipeline. The workflow here is direct: upload the product image, ask for a short hero motion, specify background, camera path and product behavior, then create platform-specific versions in 16:9 and 9:16.
This pays when the product is hard to understand from a static image. Shoes, bags, home goods, beauty tools, desk accessories and small appliances all benefit from motion that shows scale, texture and use context.

3. Agencies producing rough cuts before production
An agency can use Gemini Omni Flash as a pre-production surface. Instead of pitching a storyboard as frames, it can show three motion directions: steady product macro, handheld lifestyle shot or fast social montage. The client can react to motion, pacing and mood before anyone books a shoot.
The payoff is decision quality. Clients often approve a written concept, then dislike the moving version. A rough AI clip makes those disagreements visible earlier.
4. Real estate teams making listing teasers
A realtor can use property photos as references and prompt a short listing teaser: exterior approach, living room pan, kitchen detail, sunset patio. The important line is restraint. This should market the property style, not fake a walkthrough or invent features.
The payoff is attention. Empty listing pages compete badly in social feeds. A short, clearly AI-assisted teaser can give an agent a faster way to package a listing for Instagram, YouTube Shorts or local ads.
5. Training teams turning boring procedures into scenes
Operations teams can turn a written process into a visual sequence: a warehouse receiving step, a safety checklist, a customer handoff, a retail opening routine. Since Omni can prompt timing events, a trainer can ask for a three-part sequence where each step happens at a specific moment.
The payoff is comprehension. A new employee may ignore a PDF, but a clear visual clip can show what "good" looks like before they do the work.
6. Creators making recurring format clips
A creator can define a repeatable format: a single continuous shot, no dialogue, one word on screen each second, specific music style, and a consistent visual rhythm. Then the creator can change the topic while keeping the format recognizable.
The payoff is production rhythm. The creator still needs taste, but the model can reduce the friction between idea and publishable draft.
7. Product teams prototyping in-product video moments
A product team can mock a feature launch video, onboarding animation or in-app success moment before design and motion teams commit. Because Gemini Omni Flash supports text in videos, teams can also test whether a simple visual label or sign would clarify the message.
The payoff is alignment. Product, growth and design teams can react to the same moving artifact instead of arguing from static mockups.
What is worth building with it
The strongest opportunity is a prompt-based video variant editor for ad teams. It sits between a general video generator and a full creative suite: upload source assets, generate a base clip, then make controlled variations while preserving the scene.
The demand is already visible. DFS shows 27,100 monthly searches for ai video editor, with transactional intent. The same dataset shows 320 monthly searches for ai powered video ads, low keyword difficulty and a very high $97.83 CPC. That is a small phrase, but a strong buying signal. The SERP questions are also product-shaped: "Is there an AI that can edit my video?", "Can ChatGPT do video editing?" and "Which AI is best to edit videos?"
The MVP is narrow: connect product images, brand rules and approved prompt presets; generate a first 9:16 clip; then expose edit buttons for lighting, background, pacing, text, sound and call-to-action. The catch is sameness. If every customer gets the same template, the product becomes a wrapper. The moat is brand memory, performance feedback and controlled edit presets that make each next clip more useful.
The second opportunity is an image-to-video product studio for ecommerce catalogs. DFS shows 40,500 monthly searches for image to video ai, and the related searches are full of friction: "without login", "free without watermark", "free unlimited" and "with prompt online free." That is not all high-intent revenue, but it proves a massive top of funnel.
The MVP is a SKU workflow: upload product image, choose scene type, choose marketplace or ad format, generate a clip, then batch resize and export. The catch is margin. Broad image-to-video is crowded with Canva, Adobe, VEED, Pixlr and smaller generators in the top results. A sellable version needs a vertical wedge, such as beauty product demos, Etsy listings or Amazon hero clips.
The third opportunity is a production-safe AI video editor for internal training. It would let a manager turn SOPs into short clips, edit with plain English and keep a library by role or location. The demand is less obvious in keyword volume, but the buyer pain is real: training teams need consistent visual explanation, not viral content.
The MVP is a controlled generator with approved style, no public sharing by default, file retention rules and a review queue. The catch is compliance. Content safety, retention and audit trails matter more than raw model quality in this category. Google retains paid-tier Interactions for 55 days by default unless store=false, and store=false removes later editing through previous_interaction_id, so product design has to choose between privacy posture and editability.

What it does not solve
Gemini Omni Flash does not remove taste. It makes more video attempts possible, which means teams need stronger filters, not weaker ones.
It also does not replace every video tool. Google says video extension and interpolation are not supported. It does not support voice editing. It does not support uploaded audio references in the current API version. It does not support using YouTube videos as media sources. It does not support reasoning across multiple videos, and Google says attempting multi-video prompting may degrade performance.
There are regional constraints too. Editing uploaded videos is not currently available for users in the EEA, Switzerland and the UK, although editing videos generated by the model is supported. Uploading and editing images containing minors is not supported in those same regions, and uploading or editing images containing certain recognizable people is not supported.
There are product tradeoffs. If you want fastest synchronous generation, Google recommends background=false, store=false and stream=false. But if you set store=false, you cannot use previous_interaction_id for later edits. That is the central product decision: speed and less storage, or stateful editing.
My take: use Gemini Omni Flash when the core value is controlled iteration. Do not use it when you need exact frame-level continuity, long-form editing, voice replacement, multi-video reasoning or a fully deterministic brand asset. The model is strongest when the user can say, "that was close, keep the scene, change this one thing."
How this compares to the current market
The market already pays for AI video tooling. Runway lists paid plans from $15 to $95 per month before enterprise. Kapwing lists Pro at $24 monthly or $16 annually, and Business at $64 monthly or $50 annually. Adobe Firefly lists plans from $9.99 to $199.99 per month.
That pricing matters because Gemini Omni Flash is not only competing with other models. It is becoming raw material for better workflow products. The winners will not be the teams that expose a blank prompt box. The winners will package the prompt box into a repeatable job: edit this ad, animate this product, make this training clip, keep everything else the same.
If you want broader tool comparisons, I already keep a separate list of the best AI video generators and the best AI image-to-video generators. If you want the adjacent Google image model context, the closest sibling is Nano Banana, because it trained users to expect prompt-based visual edits instead of traditional tool panels.
Is there an AI that can edit my video?
Yes. Gemini Omni Flash supports stateful video editing through follow-up prompts, using previous_interaction_id to build on the prior generated video. Uploaded-video editing is also supported through the Files API where available, but Google lists regional restrictions and several editing limits.
Can ChatGPT do video editing?
That question appears in the ai video editor SERP, but Gemini Omni Flash is Google's API model for this specific workflow. The useful comparison is not brand name versus brand name. It is whether the tool can preserve video state, accept reference media and apply narrow edits without restarting the whole scene.
Which AI is best to edit videos?
For general browser editing, tools like Kapwing, Adobe, Canva and InVideo already rank for the job. Gemini Omni Flash is more interesting for builders because it gives them an API surface for prompt-based generation and follow-up edits, not just a finished consumer app.
What are people searching for around image-to-video AI?
DFS related searches for image to video ai include prompt-based, free, no-login and no-watermark variants. That means the market has a huge curiosity layer, but a paid product needs a sharper buyer than "turn any image into a video."
If you want one of these video workflows built around your business, start with the AI production systems service.
Jul 4, 2026